packaged_task代码解析
调用:auto task = std::packaged_task<int(int a, int b)>(Test);阅读全文→
libIXWebSocket的使用DEMO
include "libIXWebSocket/libIXWebSocket.h"阅读全文→
VSCode终端(Windows Terminal)文本出现纯色背景问题解决方法
不知道是最近的哪一次自动更新,当 Windows Terminal 背景透明度不为100%时,PowerShell 的文字会出现黑色的纯色背景,排查了终端美化工具和配色设置均没发现问题,最后发现该Bug跟PowerShell中的 PSReadline 模块相关。阅读全文→

win32程序实现最小化到托盘
POINT pt; GetCursorPos(&pt);
SetForegroundWindow(m_hWnd); //右击后点别地可以清除“右击出来的菜单”
HMENU hMenu; //托盘菜单 win32程序使用的是HMENU,如果是MFC程序可以使用CMenu
hMenu = CreatePopupMenu();//生成托盘菜单
AppendMenu(hMenu, MF_STRING, WM_ONCLOSE, _T("退出"));
int cmd = TrackPopupMenu(hMenu, TPM_RETURNCMD, pt.x, pt.y, NULL, m_hWnd, NULL);
if(cmd == WM_ONCLOSE)
{
//退出程序
m_nid.hIcon = NULL;
Shell_NotifyIcon(NIM_DELETE, &m_nid);
::PostQuitMessage(0);
}使用jsoncpp作为全局对象的成员变量的bug
今天在工程中使用jsoncpp时,发现一个问题。
现在把问题用一个demo重现出来。如下:
#ifndef _USER_STORE_H_
#define _USER_STORE_H_
class UserStore
{
public:
UserStore();
virtual ~UserStore();
private:
Json::Value m_jvData;
public:
void Login();
};
#endif
//cpp文件
#include "pch.h"
#include "UserStore.h"
UserStore::UserStore()
{
}
UserStore::~UserStore()
{
}
void UserStore::Login()
{
m_jvData["a"] = "123123";
return;
}调用如下:
...
// 全局变量:
UserStore theStore;
int APIENTRY wWinMain(_In_ HINSTANCE hInstance,
_In_opt_ HINSTANCE hPrevInstance,
_In_ LPWSTR lpCmdLine,
_In_ int nCmdShow)
{
....
}
LRESULT CALLBACK WndProc(HWND hWnd, UINT message, WPARAM wParam, LPARAM lParam)
{
switch (message)
{
case WM_COMMAND:
{
int wmId = LOWORD(wParam);
// 分析菜单选择:
switch (wmId)
{
case IDM_ABOUT:
theStore.Login();
break;
...退出程序后,显示
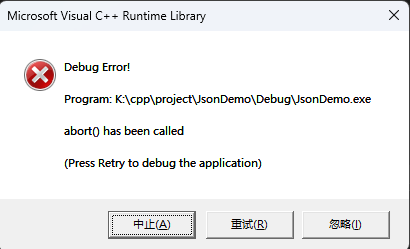
问了deepseek和chatgpt都没啥用,后百度搜索如下内容:
发现在json_value.cpp调用下面语句时崩溃。
{
value_.string_ = valueAllocator()->duplicateStringValue( value );
}查看 valueAllocator() ,在src\lib_json\json_value.cpp里,他是一个函数,如下:
static ValueAllocator *&valueAllocator()
{
static DefaultValueAllocator defaultAllocator;
static ValueAllocator *valueAllocator = &defaultAllocator;
return valueAllocator;
}它是取得一个静态变量的针指。
调试发现在使用valueAllocator()时,即DefaultValueAllocator 对象指针时。DefaultValueAllocator 对象已经被析构了。
因为c++中不同的cpp文件中,全局对象和静态对象 构造和析构 顺序是不确定的。
son_value.cpp再看往下看。可以看到。
static struct DummyValueAllocatorInitializer
{
DummyValueAllocatorInitializer()
{
valueAllocator(); // ensure valueAllocator() statics are initialized before main().
}
} dummyValueAllocatorInitializer;它的作用是确保valueAllocator()在main()函数前被调用。(注意:先构造的后析构,后构造的先析构)
但其实这样还不能确保在比其它全局对象的构造函数先调用,比其它全局对象晚析构。问题就出在这里了。
解决方案1:
不在全局对象析构函数中使用jsoncpp字符串。就没问题了。
但有时候会在全局对象析构函数保存一些数据,把它转成json格式后再存盘。所以这个解决方案,治标不治本。
解决方案2:
提前对 DefaultValueAllocator 类对象进行构造,比其它【全部对象】或【静态对象】更前构造,这样DefaultValueAllocator也会比他们更晚析构。
可以在 DummyValueAllocatorInitializer 前面加上一个编译指令 #pragma init_seg(lib) 如下:
#pragma init_seg(lib) // add by fangyukuan 2012.5.6
static struct DummyValueAllocatorInitializer
{
DummyValueAllocatorInitializer()
{
valueAllocator(); // ensure valueAllocator() statics are initialized before main().
}
} dummyValueAllocatorInitializer;这个方案,不好的地方就是修改了第三方库。一般我们是不会去修改第三方库的。
你有更好方案吗?有,请告诉我。
其它:
我们再来看看 DefaultValueAllocator 类,都做了些什么?代码如下:
class DefaultValueAllocator : public ValueAllocator
{
public:
virtual ~DefaultValueAllocator()
{
}
virtual char *makeMemberName( const char *memberName )
{
return duplicateStringValue( memberName );
}
virtual void releaseMemberName( char *memberName )
{
releaseStringValue( memberName );
}
virtual char *duplicateStringValue( const char *value,
unsigned int length = unknown )
{
//@todo invesgate this old optimization
//if ( !value || value[0] == 0 )
// return 0;
if ( length == unknown )
length = (unsigned int)strlen(value);
char *newString = static_cast<char *>( malloc( length + 1 ) );
memcpy( newString, value, length );
newString[length] = 0;
return newString;
}
virtual void releaseStringValue( char *value )
{
if ( value )
free( value );
}
};上面是方法一和方法二实验后均可以解决问题,我的实验方法三也能解决,随便写个值:
UserStore::UserStore()
{
m_jvData["xxxx"] = 1111;
}临时std::future对象销毁造成的阻塞问题解析
运行如下代码
void main() {
// 临时future对象将在语句结束时销毁
std::async(std::launch::async, []{
std::this_thread::sleep_for(std::chrono::seconds(2));
std::cout << "Async task completed\n";
});
std::cout << "Function continues\n";
}在这个代码里,你会惊讶地发现 "Function continues" 会在2秒后才输出,而不是立即输出,为什么?
原因如下:
标准规定 (C++11及以上),当从 std::async 返回的 future 对象被销毁时:如果这是最后一个引用该共享状态的 future,且异步任务还未完成,则析构函数会阻塞等待任务完成。
设计成这样主要是为了以下的思考
异常安全:确保异步任务中的异常不会被无声丢弃
资源管理:防止任务未完成时资源提前释放
确定性:避免程序退出时仍有后台线程运行
解决方案:
保存future对象
std::future<void> taskFuture; // 成员变量或长期存在的对象
void startAsyncTask() {
taskFuture = std::async(std::launch::async, []{
// 长时间运行的任务
});
// future生命周期延长,不会立即阻塞
}memset的内部实现及缺陷
memset 的具体实现的代码大概如下:
//实现方式是逐字节写入
void* memset(void* dest, int ch, size_t count) {
unsigned char* p = (unsigned char*)dest;
while (count--) {
*p++ = (unsigned char)ch;
}
return dest;
}memset 的注意事项
仅适用于字节级填充
memset 是按字节填充的,所以:
memset(a, 0, sizeof(a)) ✅(0 的字节模式是 0x00)
memset(a, -1, sizeof(a)) ✅(-1 的字节模式是 0xFF)
memset(a, 20, sizeof(a)) ❌(20 的字节模式是 0x14,但 int 可能是 0x14141414,不符合预期)
不能用于初始化非平凡类型(如类对象)
memset 会破坏 C++ 对象的内部结构(如虚表指针),导致未定义行为(UB)。
对于需要初始化某个值的数组可以用如下方法:
1、使用循环对每个变量初始
for(int i 0; i < 100; i++)
a[i] = 20;2、使用 std::fill 或 std::fill_n(需要包含 )
int a[100];
std::fill(std::begin(a), std::end(a), 20); // 全部填充为 20
或者
std::fill_n(a, 100, 20); // 填充前 100 个元素为 203、使用 std::array(推荐,更现代的方式)
#include <array>
#include <algorithm>
std::array<int, 100> a;
a.fill(20); // 全部填充为 20
或者
std::fill(a.begin(), a.end(), 20);Win11右键恢复旧右键菜单的方法和命令
执行如下三个命令即可。
reg add "HKCU\Software\Classes\CLSID\{86ca1aa0-34aa-4e8b-a509-50c905bae2a2}\InprocServer32" /f /ve结束explorer.exe
taskkill /f /im explorer.exe启动explorer.exe
start explorer.exeVSCODE 配置用户代码片段:通过header添加避免重复包含问题
VSCODE 配置用户代码片段:通过header添加避免重复包含问题。
{
"c c++ Header": {
"scope": "c,cpp",
"prefix": "header",
"body": [
"#ifndef __${TM_FILENAME_BASE/(.*)/${1:/upcase}/}_H__",
"#define __${TM_FILENAME_BASE/(.*)/${1:/upcase}/}_H__",
"",
"$0",
"",
"#endif /* __${TM_FILENAME_BASE/(.*)/${1:/upcase}/}_H__ */"
],
"description": "Add #ifndef,#define and #endif"
}
}STC单片机的ISP协议
两年前,曾经用过 STC的单片机,当时对他的那个ISP下载功能很是感兴趣,且当时也想实现一个IAP 升级办法,又不想占用他现有的fash 空间,毕竟还是有点小。就想办法着手研究了一下,就写了一段代码在8051内核的64K空间依次读取所有的数据,最后得到了一个 2k 多一点的 ISP 所用的 bin 文件,反汇编得到汇编文件,就在那花功夫细细地看了看实现方法,分析得出了基本的下载协议,两年后,我觉得这些东西可以考虑公开了。阅读全文→
使用单片机对其它单片机进行ISP下载程序
通过第三方程序实现对STC单片机的程序下载,可以方便进行现场的调试和更新。特别是对于设计远程程序更新、无线程序下载与调试等功能有帮助。阅读全文→
std::promise的工作原理和使用
std::promise 提供了一种灵活的方式来在不同线程之间传递几乎任何类型的数据。阅读全文→
std::tuple(元组)介绍与使用
C++11引入了一个新的较实用的模板类型,std::tuple,也即是元组。元组是一个固定大小的不同类型(异质,heterogeneous)值的集合,也即它可以同时存放不同类型的数据。C++已有的std::pair类型类似于一个二元组,可看作是std::tuple的一个特例,std::tuple也可看作是std::pair的泛化。std::pair的长度限制为2,而std::tuple的元素个数为0~任意个。阅读全文→
串口通讯超时的设置与含义
COMMTIMEOUTS:COMMTIMEOUTS主要用于串口超时参数设置。COMMTIMEOUTS结构如下:
typedef struct _COMMTIMEOUTS {
DWORD ReadIntervalTimeout;
DWORD ReadTotalTimeoutMultiplier;
DWORD ReadTotalTimeoutConstant;
DWORD WriteTotalTimeoutMultiplier;
DWORD WriteTotalTimeoutConstant;
} COMMTIMEOUTS,*LPCOMMTIMEOUTS; 间隔超时=ReadIntervalTimeout
总超时 = ReadTotalTimeoutMultiplier * 字节数 + ReadTotalTimeoutConstant
串口读取事件分为两个阶段(我以Win32 API函数ReadFile读取串口过程来说明一下)
第一个阶段是:串口执行到ReadFile()函数时,串口还没有开始传输数据,所以串口缓冲区的第一个字节是没有装数据的,这时候总超时起作用,如果在总超时时间内没有进行串口数据的传输,ReadFile()函数就返回,当然 没有读取到任何数据。而且,间隔超时并没有起作用。
第二阶段:假设总超时为20秒,程序运行到ReadFile(),总超时开始从0 计时,如果在计时到达10秒时,串口开始了数据的传输,那么从接收的第一个字节开始,间隔超时就开始计时,假如间隔超时为1ms,那么在读取完第一个字节后,串口开始等待1ms,如果1ms之内接收到了第二个字节,就读取第二个字节,间隔超时重置为0并计时,等待第三个字节的到来,如果第三个字节到来的时间超过了1ms,那么ReadFile()函数立即返回,这时候总超时计时是没到20秒的。如果在20秒总计时时间结束之前,所有的数据都遵守数据间隔为1ms的约定并陆陆续续的到达串口缓冲区,那么就成功进行了一次串口传输和读取;如果20秒总计时时间到,串口还陆陆续续的有数据到达,即使遵守字节间隔为1ms的约定,ReadFile()函数也会立即返回,这时候总超时就起作用了。
总结起来,总超时在两种情况下起作用
第一:串口没进行数据传输,等待总超时时间那么长ReadFile()才返回。非正常数据传输
第二:数据太长,总超时设置太短,数据还没读取完就返回了。读取的数据是不全的
间隔超时触发是有条件的
第一:在总超时时间内。
第二:串口进行了数据的传输。
成功的进行一次串口数据的传输和读取,只有总超时和间隔超时相互参与配合才能完成